Initial version released.
Dropincc.java is a dynamic parser generator which allows you crafting your DSLs in pure java, using your favorite editor.
Now it reached its initial release version 0.1.0. You can download it from the project page and play around with it.
There’s a detailed Quick Start guide on the project page, it could guide you through to have a overall feeling on using dropincc.java.
Main attributes of Dropincc.java.
- It’s not just ‘yet another compiler compiler’. It aims to help you building DSLs in java Dynamically.
- Dynamic means you can use your newly defined DSL immediately after you have just finished its definition. No other steps required, no additional command-line instructions needed to type.
- Very close to EBNF grammar syntactically when defining grammar rules using dropincc.java. With the fluent interface API, you can feel as if you are writing EBNF directly. Syntactically close to EBNF is very nice for a parser generator.
- It generates LL(*) parser for your language, dynamically, using java 1.6’s compiler API. And it provide powerful semantic predicate mechanics to handle even context-sensitive situations.
- It won’t generate a parser source file to you and telling you to place the file into some where of your project directory. Instead, it handles all those generation & compiling staff in the background and only provides you a executable object which you can invoke.
- No other dependencies except for the built-in java library. Requires JDK 1.6 or above.
A dummy language example.
Requires JDK 1.6 or above. Firstly, place the dropincc jar file in your class path.
And then, crafting your language’s EBNF definition:
Let’s define a language which accepts arbitrary numbers of quoted ‘a’ or ‘bc’. For example: ‘(a)(bc)’, ‘(bc)((a))’ or ‘(((bc)))(bc)’, the numbers of pairs of parentheses is unlimited.
The EBNF of this dummy language:
S ::= L $
L ::= Q*
Q ::= 'a'
| 'bc'
| '(' Q ')'
Ok, after defining the EBNF representation of our language, it’s time to translate the EBNF into dropincc.java representation. I say ‘translate’ here because this is a line-by-line straightforward step:
public static void main(String... args) throws Throwable {
Lang lang = new Lang("Dummy");
TokenDef a = lang.newToken("a");
TokenDef bc =lang.newToken("bc");
TokenDef lp = lang.newToken("\\(");
TokenDef rp = lang.newToken("\\)");
Grule L = lang.newGrule();
Grule Q = lang.newGrule();
lang.defineGrule(L, CC.EOF); // S ::= L $
L.define(CC.ks(Q));// L ::= Q*
/*
* Q ::= 'a'
* | 'bc'
* | '(' Q ')'
*/
Q.define(a)
.alt(bc)
.alt(lp, Q, rp);
}
Ok, we have done defining the grammar rules of our dummy language, so easy:
- Define tokens, using built-in java regular expression syntax. And define rules, say, ‘Grule’s in dropincc.java. TokenDefs and Grules are basic elements of defining grammar rules.
- You just using your defined TokenDefs and Grules to express your grammar, just like writing EBNF.
- Elements concatenations are expressed by comma separated sequences:
L, CC.EOFmeansL $. CC.EOF is a predefined TokenDef provided by dropincc.java. - Alternative productions of a grammar rule is expressed by a
altmethod call on a grule element. For example, theQrule has three alternative productions. - The kleene star(means zero or more) and kleene cross(means one or more) notation is expressed by
CC.ksandCC.kcutility functions. See the line:L.define(CC.ks(Q));// L ::= Q*.
That’s almost all you need to learn about how to define a grammar using dropincc.java.
After that, you can compile your grammar:
Exe exe = lang.compile();
This step would make you a callable object named ‘exe’. You can use this object to eval and test your newly defined language:
System.out.println(exe.eval("a(a)((bc))"));
This would print the output: [Ljava.lang.Object;@67a5a19. It’s an object array which holds the whole parse tree:
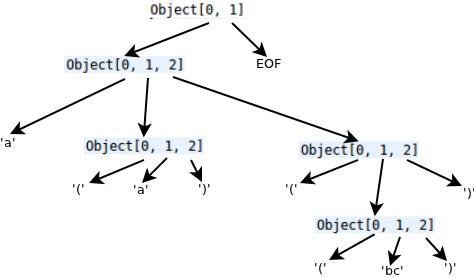
But it’s useless just getting the parse tree. We should do something to manipulate the parse tree and produce some ‘results’ of this parsing.
Ok, suppose we have a dummy task: to remove all parentheses from the input string, leaving only the 'a' and 'bc's there. Then at last, return the resulting string as the return value of eval method call on exe.
This involves adding actions to the grammar. The actions are some kind of code block, it should execute when its’ corresponding grammar rule production matches.
In dropincc.java, actions are implemented by closures, using the Action interface. We try to add an action to the Q rule:
Q.define(a).action(new Action() {
public String act(Object matched) {
return (String) matched;// string 'a'
}
}).alt(bc).action(new Action() {
public String act(Object matched) {
return (String) matched;// string 'bc'
}
}).alt(lp, Q, rp).action(new Action() {
public String act(Object matched) {
// returns the middle element matched, that's the returned value of the enclosing 'Q' rule
return (String) ((Object[]) matched)[1];
}
});
Above is the Q rule with three actions, each action for one alternative production. In fact since the first two actions does noting but just returning the matched string, so they are not necessary. The Q rule with action could be defined as follows:
Q.define(a)
.alt(bc)
.alt(lp, Q, rp).action(new Action() {
public String act(Object matched) {
// returns the middle element matched, that's the returned value of the enclosing 'Q' rule
return (String) ((Object[]) matched)[1];
}
});
Leaving only the third action there. The third action, returned the middle element matched of its production(ignored left and right parentheses). The middle element matched is the return value of the recursively enclosing Q rule.
The action for L rule is quite simple and significant: it collects all strings matched and concatenates them into a whole large string, then return the resulting string:
L.define(CC.ks(Q)).action(new Action() {
public String act(Object matched) {
Object[] ms = (Object[]) matched;
StringBuilder sb = new StringBuilder();
for (Object m : ms)
sb.append(m);
return sb.toString();
}
});// L ::= Q*
Then the last top-level rule’s action: just return the value of L rule, just ignoring EOF:
lang.defineGrule(L, CC.EOF).action(new Action() {
public String act(Object matched) {
return (String) ((Object[]) matched)[0];
}
}); // S ::= L $
Ok, we can now run the program again and could see it prints out the output: aabc, with all parentheses removed.
The whole program in a gist:
You can download and play around with it on your own.
Dropincc.java is currently on its very initial stage. It has some major improvements to be done:
- It uses java’s built-in regEx implementation to support token definition, so it couldn’t do ‘longest match’ currently. This should be fixed later.
- Due to some LL(*) analysis issues, ‘Non-LL regular’ exceptions may be thrown when it encounters some special case of grammar rules. This must be fixed soon.
There is a more practical Hello World example which implements a full-featured calculator in the quick start guide of dropincc.java. On its project home page. Go and check out there if you like.